Networks
Privacy by design in data mining
|
Permalink
Dino Pedreschi, Anna Monreale, and Fosca Giannotti
27 February 2012
A privacy by design paradigm can be included in knowledge discovery technology to counter potential privacy violations without obstructing the information gained by data mining.
Today, we are able to discover and store increasing amounts of detailed data on human activities: automated payment systems record our purchases; search engines record logs of our queries on the Internet; mobile devices record the trajectories of our movements; and so on. Such information is at the heart of the idea of a ‘knowledge society’, in which our understanding of social phenomena is sustained by data mining (i.e., discovering patterns in data sets using artificial intelligence and machine learning techniques as well as statistics and database systems). Thus, by analyzing these digital traces using data mining technology, we can create improve our understanding of complex aspects of society, such as mobility behavior, economic and financial crises, the spread of epidemics, the diffusion of opinions, and so on. However, given the sheer volume of personal and sensitive information stored on personal computers and the Internet, one serious problem is preventing privacy violations. Does data mining encroach upon an individual's right to have full control of his or her personal information? The problem becomes even more serious when we consider how much information can be discovered by linking different forms of data together.
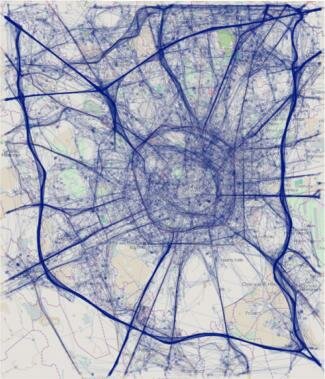
Figure 1.
An example of global positioning system (GPS) trajectories from Milan, Italy.
Figure 2.
A data-driven, anonymizing transformation of the GPS data in Figure 1. The process involves (a) extracting characteristic points, (b) performing spatial clustering, c) partitioning the space using Voronoi tessellation and (d) transforming the original trajectories.

It is evident that maintaining control of personal data is increasingly difficult and cannot simply be accomplished by de-identification (i.e., by removing the direct identifiers contained in the data). Many examples of re-identification from supposedly anonymous data have been reported in the scientific literature and media, from health records1 to query logs2 and global positioning system (GPS) trajectories.3 In the past few years, several techniques have been proposed to develop technological frameworks for countering privacy violations, without losing the benefits of data mining technology. Despite these efforts, no general method exists that is capable of handling both generic personal data and preserving generic analytical results.
Our idea is to inscribe privacy protection into the knowledge discovery technology by design, so that the analysis incorporates the relevant privacy requirements from the start.4 Here, we evoke the concept of ‘privacy by design’, a term coined in the 1990s by Ann Cavoukian, the Information and Privacy Commissioner of Ontario, Canada. Briefly, privacy by design refers to the philosophy and approach of embedding privacy into the design, operation and management of information processing technologies and systems.
In the data mining domain, the general ‘by design’ principle is that higher protection and quality can be achieved in a goal-oriented approach.4 In such an approach, the data mining process is designed while making assumptions about the sensitive personal data being mined, the attack model (i.e., the knowledge and purpose of a malicious party) and the category of analytical queries that are to be answered using the data.
These assumptions are fundamental to the design of a privacy-preserving framework. Firstly, the techniques for privacy preservation strongly depend on the nature of the data being protected. For example, methods suitable for social networking data would not be appropriate for trajectory data. Secondly, a valid framework has to determine the attack model based on the background knowledge an adversary would use and then define an adequate countermeasure. Different assumptions on the background knowledge entail different defense strategies. For example, an attacker could possess partial information about a person's mobility behavior and use it to infer all of their movements. In other cases, the attacker could obtain data by means that do not ensure precise information. Indeed, a defense strategy designed for counter attacks based on approximate knowledge might be too weak in the case of detailed knowledge. Finally, a privacy-preserving strategy should find an acceptable trade-off between data privacy and data utility. To reach this goal it is fundamental that we consider the categories of analytical queries to be answered using the transformed data, which would therefore enable us to determine which data properties to preserve. For example, the design of a defense strategy for spatio-temporal data should consider that this data could be used to analyze collective mobility behavior in a city.
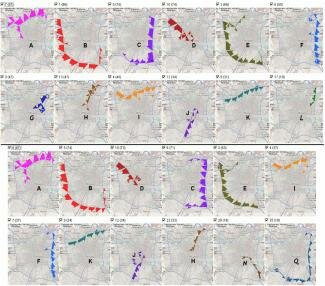
Figure 3.
Clusters derived from original data (top) and from anonymized data (bottom).
Under the above assumptions, we claim that it is possible to design a privacy-preserving analytical process that can anonymize data with a quantifiable privacy guarantee, providing a measurable probability that a malicious attack will fail. For example, in one approach5 we considered the trajectory-linking attack where a malicious party, M, knows a sequence of locations a person, R, has visited, and wants to find all places visited by R. The challenge was to guarantee that the probability of success of this attack is very low while preserving the utility of the data.
The trajectories in Figure 1 were obtained from a massive data-set of GPS traces in the city of Milan, Italy. Although publishing these raw trajectories is clearly unsafe, one possibility is to use a data-driven, anonymizing transformation3 to reduce the probability of re-identification. In this transformation, characteristic points are extracted from the original trajectories: start points, end points, turning points, and significant stop points: see Figure 2(a). These characteristic points are then clustered into small groups by spatial proximity: see Figure 2(b). Next, the central points of the groups are used to partition the space by means of Voronoi tessellation: see Figure 2(c). Finally, each original trajectory is transformed into the sequence of Voronoi cells that it crosses: see Figure 2(d).
Additional techniques can further reduce the probability of re-identification, obtaining a safe theoretical upper bound for the worst case (i.e., the maximum probability that the linking attack succeeds). In our example, we show how the probability of success is bounded by 1/20, but the upper bound for 95% of the attacks is below 10−3. Thus, the transformed trajectories are orders of magnitude safer than the original data. Most importantly, we are still able to use the transformed data to discover trajectory clusters and can we still identify groups of trajectories sharing common mobility behavior. Figure 3 illustrates the most relevant clusters found by mining the original trajectories (top) and using the anonymized trajectories (bottom). The resulting clusters appear very similar in the two cases, which is confirmed by various cluster comparison quantities, such as the F-measure.
By including privacy protection in knowledge discovery technology by design, it is possible to ensure valid analytical results with concrete formal safeguards. This will also make possible measurements of the extent of protection with respect to the linking attack. In future, we would like to study the applicability of the privacy by design paradigm to other complex analytical processes, such as social network data.
Authors
Dino Pedreschi
Department of Computer Science University of Pisa
Dino Pedreschi is a full professor of computer science whose current research interests are in data mining and logic in databases, particularly in data analysis, spatio-temporal data mining, and in privacy-preserving data mining. He is also a member of the Knowledge Discovery and Data Mining Laboratory (KDD-Lab), a joint research group with the Information Science and Technology Institute of the National Research Council in Pisa. He is an associate editor of the journal Knowledge and Information Systems. He was granted a Google Research Award (2009) for his research on privacy-preserving data mining and anonymity-preserving data publishing.
Anna Monreale
Department of Computer Science University of Pisa
Anna Monreale is a post-doctoral researcher and a member of the KDD-Lab. Her research is in anonymity of complex forms of data, including sequences, trajectories of moving objects and complex networks, and privacy-preserving outsourcing of analytical tasks.
Fosca Giannotti
Department of Computer Science University of Pisa
Fosca Giannotti is a senior researcher at the ISTI-CNR, where she leads the KDD-Lab. Her recent research interests include data mining query languages, mining spatio-temporal and mobility data, privacy-preserving data mining, and complex network analysis. She has been the coordinator of various European-wide research projects, including Geographic Privacy-aware Knowledge Discovery and Delivery (GeoPKDD). She is the author of more than 100 publications and served as PC chair and PC member in the main conferences on Databases and Data Mining. She is the co-editor of the book Mobility, Data Mining and Privacy (Springer, 2008).
References
-
L. Sweeney, k-Anonymity: a model for protecting privacy, Int'l J. Uncertainty Fuzziness Knowledge Based Syst. 10 (5), pp. , 2002.
-
M. Barbaro and T. Zeller, A Face Is Exposed for AOL Searcher No. 4417749, The New York Times. http://www.nytimes.com/2006/08/09/technology/09aol.html?pagewanted=all
-
K. Biermann, Was Vorratsdaten über uns verraten, The Zeit online. http://www.zeit.de/digital/datenschutz/2011-02/vorratsdaten-malte-spitz
-
A. Monreale, Privacy by Design in Data Mining, 2011. PhD thesis University of Pisa
-
A. Monreale, G. Andrienko, N. Andrienko, F. Giannotti, D. Pedreschi, S. Rinzivillo and S. Wrobel, Movement data anonymity through generalization, Trans. Data Privacy 3 (2), pp. 91-121, 2010.
DOI: 10.2417/3201202.004005